
.jpg)

计算机系统软件方面的性能优化一直是企业在技术攻关过程中需要不断突破的难题,也是 Boolan 技术赋能培训的重点内容之一。为此,我们特别将线下企业内训课程搬到线上,让更多人能有机会学习并掌握性能优化的技巧。
《C++性能优化高端培训》在线直播精品课程即将于6月22日重磅上线,由 Boolan首席咨询师、性能优化专家吴咏炜老师主讲。
讲师介绍

5月31日晚,吴咏炜老师现身 Boolan 直播间,和大家一起聊了聊《现代C++性能漫谈 》,以下为本期直播重点干货:
讲座回顾
一、影响性能的架构因素

讲优化离不开大O表示法,大O表示法虽然是算法里面非常重要的一个东西,但在我们真实的项目中是远远不够的,还有很多其他影响性能的因素,有硬件方面的,也有软件方面的。硬件方面关系比较大的是存储层次体系,还有处理器的乱序执行和流水线的问题,还有一些是并发的问题。软件方面常见的是系统调用的开销问题、编译器优化问题和语言本身的抽象性问题。
1. 硬件——存储层次体系
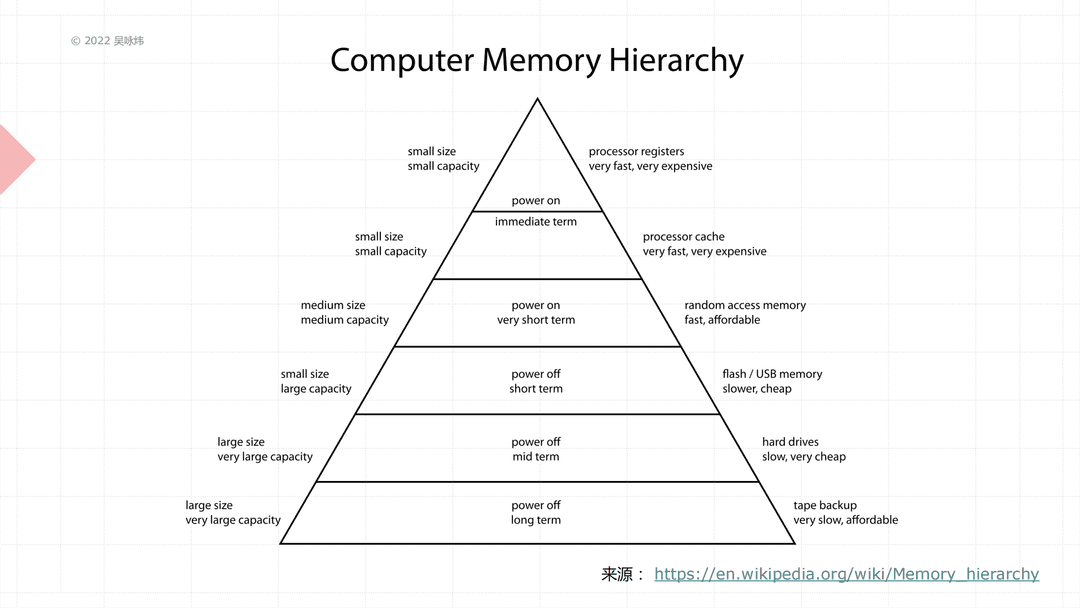
这张图讲的是计算机的存储架构问题。这个金字塔的顶端,标准是处理器里面的寄存器,它是最快、最贵的,同时也是最小的,物理尺寸和容量都非常小。往下有处理器的缓存,再往下有随机存储,再往下有闪存硬盘,到现在已经不太常见的磁带备份,我们可以看到越往下,它就越来越大,容量越来越大,速度越来越慢,价格越来越便宜,这是一个趋势,我们能不能完全使用非常快、非常贵的那种东西来做出一个大容量的计算机呢?当然理论上是可能的,但从经济学角度来讲性价比非常低。因为你并不一定所有时间都能利用得上这些快速存储的东西,我们很多时候可以分层,有一部分是快的,有一部分是慢的,只要能保证比较快地把这些慢的东西加载到快的里面去执行,这样我们价格可以做得非常低,同时性能仍然差不多,而并不是把处理器里面最快的那些东西做到容量跟下面一样大,让这个电脑的价格贵上几百万倍,性能能提升几百万倍。

以常见的 Intel Haswell 处理器为例,可以看到从上往下基本是以量级性的大小在增加,延迟也是一样量级性地增大,所以整体来看会发现存储是一定有这样一个层次的。存储层次实际上是我们软件优化当中一个非常需要注重的问题:怎么高效地利用存储,在很大程度上决定了你的代码性能。
讲性能实际上要考虑好几个因素,有一个要考虑的点就是你的程序到底瓶颈在哪里。你程序的瓶颈可能是CPU,也可能是内存,也可能是 IO。优化的处理策略也会不一样,比如,如果你的应用瓶颈在内存上的话,那你需要特别关心存储层次这个问题。
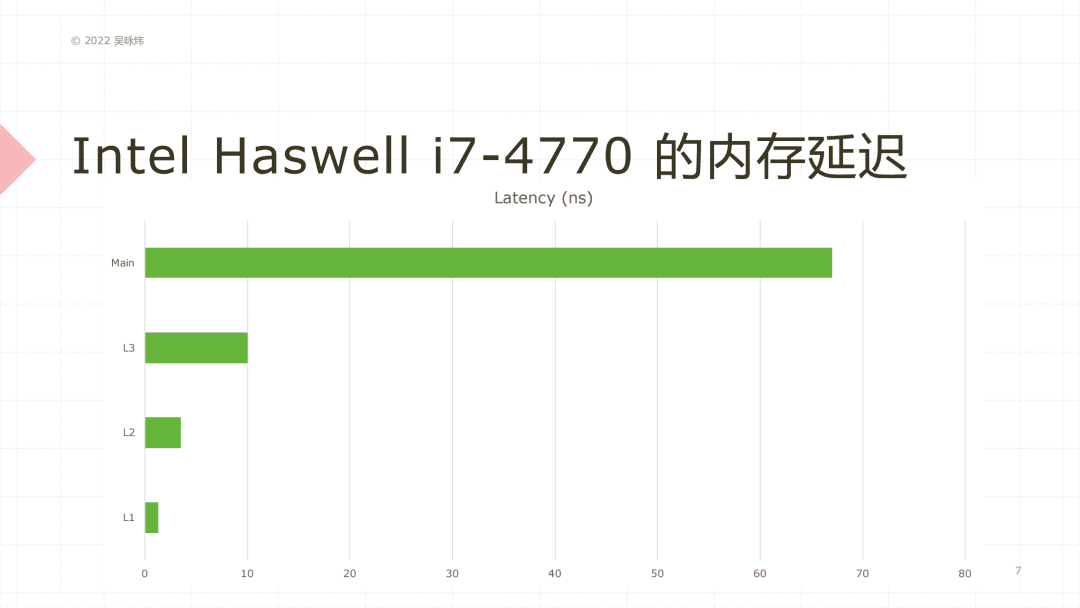
这张图看起来更直观一些,可以看到主存和 L1 差不多有50倍的性能差异。如果要访问的数据在 L1 里,那就比从主存里直接取要快50倍,如果已经在 L3 里了, 那也比主存取大概要快5-6倍。换句话说,如果你的程序大部分数据能够在 L3 缓存里存得下的话,比每次都要从主存里去取,这个性能能够提高6倍左右。
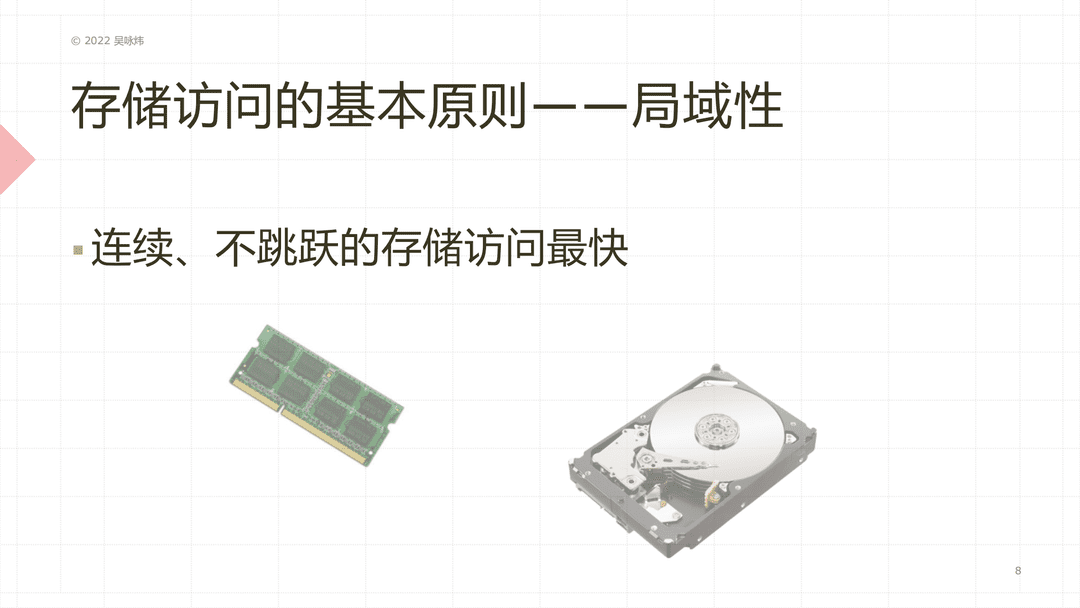
存储访问的基本原则就是局域性,连续、不跳跃的存储访问最快。这个包含代码,也包含数据。从代码的角度来讲也就意味着顺序执行,没有任何跳转,没有任何条件,这样的程序是最快的;从数据的角度来讲,连续存放的数据是最快的。如果你访问数据的时候不需要在内存里跳来跳去,这样就会比较快。当然内存本身实际上是没有这个特性的,但考虑到缓存机制,就会有这个问题,硬盘更是如此。硬盘即使不考虑缓存,都是连续访问,会比跳跃式的方面要快。
2. 硬件——处理器的乱序执行和流水线

处理器里也有所谓的乱序执行和流水线,这两个特性主要都是为了提高在单位时钟周期的处理能力。后面放的一张图就会看到为什么我们有很大的需求需要提高单位时钟周期的处理能力,它对我们程序的影响是程序一旦有分支就会打乱流水线,性能下降,也就是说程序里分支越少越好,条件语句越少越好,甚至调函数也是越少越好。
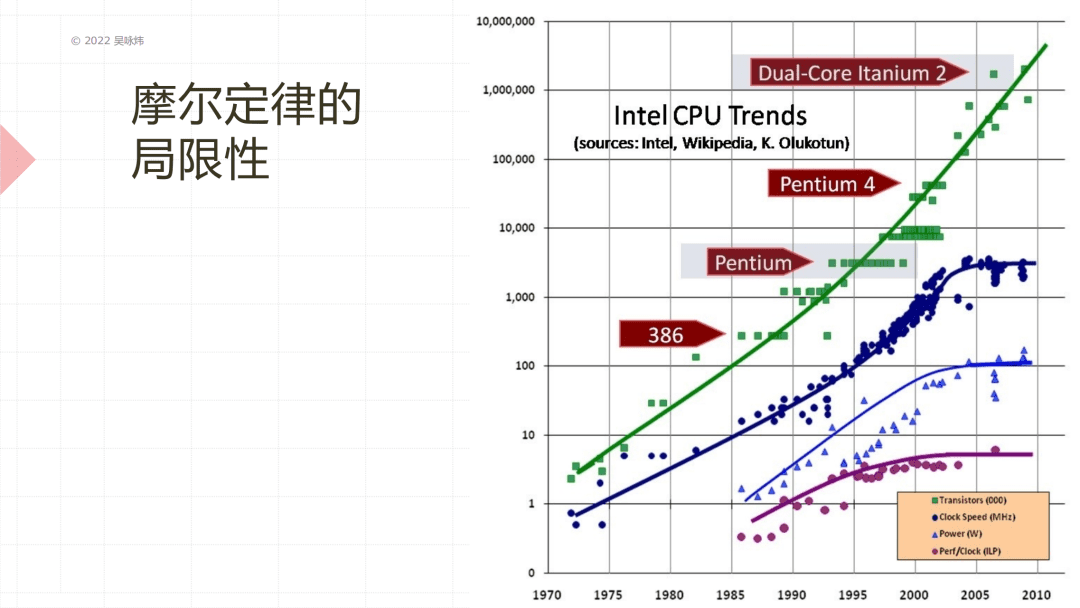
这张图表现摩尔定律的局限性,主要是说明想要利用摩尔定律带来的性能提升的话,我们已经不能利用主频的提高了,哪怕是单位时钟周期的执行的指令数提高也是非常受限的,所以我们需要主动去利用多核的并发并行方面的特性,这个是很难的。
3. 硬件——并发对编程思维带来冲击:
- 不再能假设有自然的完全执行顺序
- 开发人员也必须主动利用多核特性
- 多线程的调度和竞争成为影响性能的关键因素
- 适用于单线程的接口可能不再适用
4. 软件——系统调用开销:

除了极少数非常硬核的嵌入式开发可能会完全不需要调用操作系统,一般情况下我们总是需要调用操作系统的接口,在这种情况下就需要考虑操作系统调用本身的开销。图中列了几个系统调用,大家知道它们哪个快哪个慢吗?需要经过测试才能知道哪些比较快。我只知道其中 gettimeofday 是比较快的,在比较新的 Linux 上会是如此,因为 Linux 对 gettimeofday 有个特殊的优化,能够在系统调用时不进行用户态和核心态的切换。而大部分系统调用都要执行用户态和核心态之间的切换,就会有一个额外的开销,性能会低很多。
5. 软件——编译器优化:

编译器本身也是 C++ 里的一个大魔法,编译器的优化可以产生非常巨大的性能差异,它对 C++ 带来的性能差异的影响比 C 带来的性能影响要大得多,很大程度上是因为程序怎么写造成的。优化本身一方面能提高性能,另一方面会揭露你程序里的短处,因为优化的时候,你觉得程序这么写没问题,可能在没有优化的时候也确确实实没有问题,但是一旦打开了优化,你会发现程序里突然出了“鬼”,就是因为你的代码里可能写出了某些未定义行为。未定义行为在 C++ 里非常妖孽,但它对优化来讲也非常重要。比如空指针的解引用就是一个比较常见的未定义行为,当然在大部分现代环境里都有保护模式,一旦有非法内存访问,包括空指针,在用户态执行的程序会立即挂掉。程序挂掉实际上是件好事情,让你立即能够进行调试,知道问题出在哪里。但有很多未定义行为编译器没法发现、没法告警,然后在执行过程中你才会突然发现程序行为不正常了,你调了半天才发现,哦,原来我这里触发了一个未定义行为。
打个比方,带符号整数的溢出在 C++ 里就是一个未定义行为,你如果认为两个正整数相加有可能会变成负数,会翻转的话,那就错了。C++ 编译器有可能会认为这种情况不可能发生,这种情况下,代码的行为就可能跟你想象的行为会不一样。编译器会有一些告警选项,你还可以使用一些像 clang-tidy 这样的静态扫描工具,部分可以解决这些问题,但这也只是部分。你仍然需要了解这些。如果你不知道这些未定义行为,如果你没有打开告警选项,如果你也没利用静态扫描器,那很可能这些未定义行为会把你坑得很惨。
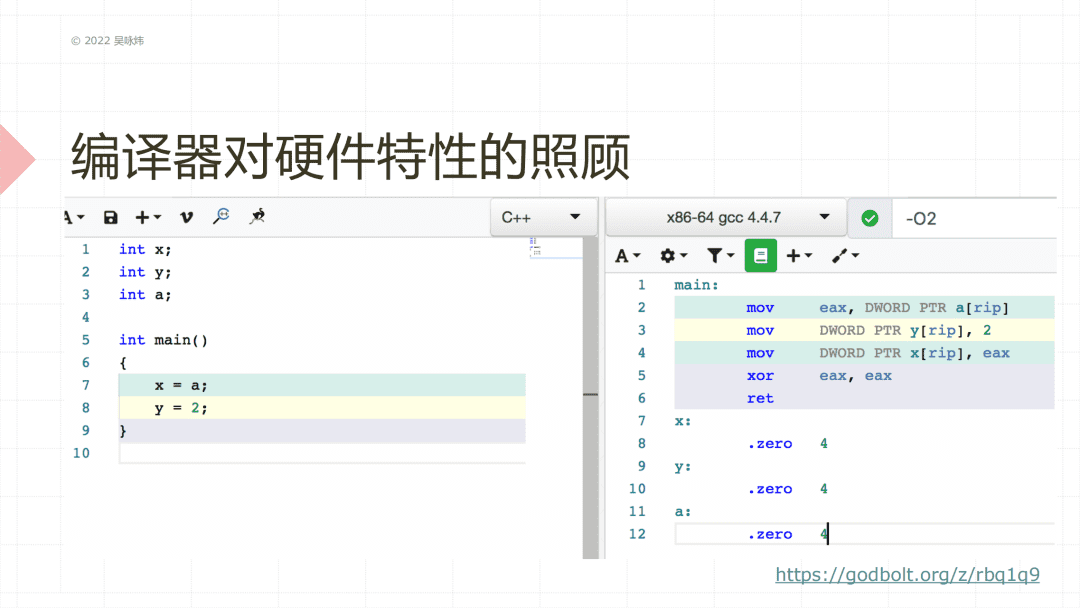
这是另外一个特殊的编译器的行为,编译器对硬件特性的照顾。它产生的代码会跟你想象的有一点点不一样。这边有x、y、a三个全局变量,看代码,比较直观的想象应该是,先写x、再写y。但是我们看一下右边图,会发现生成的汇编代码里,它先读a,再写y,再写x,这就是编译器为了照顾处理器进行了一个乱序处理。现代处理器里为了在单个周期能尽量多执行指令,内部有流水线,可以并行执行多条指令。把读a和把结果写到x里面,这两个操作有依赖关系,不能并行。所以编译器会把写y穿插进去,因为这条指令跟读a是不冲突的,可以并行执行。我们可以看到,你即使没写任何特殊的东西,编译器都可能会做一些乱序,而处理器本身也还可能会产生额外的乱序。
6. 软件——语言抽象性:

语言的抽象性,这个可能就比较好理解了,和比较直白的 C 相比起来,在 C++ 里如果写同样的 Obj obj,除了和 C 相同的步骤之外,还会调 Obj 的构造函数,当代码在执行到下面的 } ,会调用析构函数,这就是一个比较隐式的一个操作。
二、为什么要用 C++?

为什么我们要使用 C++?首先我们要贴近硬件,需要使用一些原生指令,需要高性能,需要使用一些新的特殊硬件;另一方面我们又需要使用零开销抽象。只要求贴近硬件的话,用 C 就可以,而 C++ 额外提供的就是多种不同的零开销的抽象机制,包括类、包括继承、模板等等好多东西,都是为了让你能够进行抽象,同时你这个抽象本身的开销应该是你想象中最低或者比较低的,跟你手写出来代码一样,而且在你不使用这个抽象的时候不会给你带来额外的开销。这就是 C++ 的重要特性。
C++ 的学法,我认为正确的做法是把它当成一门外语,而且是一门活跃的外语,像英语这样的外语,而不是像拉丁语。你需要持之以恒,你需要练习,你需要掌握惯用法,你还要学习一些最佳实践。

C++ 里提供了很多抽象,所以你要利用这些抽象,我们可以写出很抽象和比较简洁的代码,这就是洋葱原则的第一条:简单的事情简单做。我们不需要把所有的事情都搞得很复杂,C++ 的特点在于如果你需要的时候,C++ 给你有很多定制点,可以允许你去做很多额外的切割,你可以做些额外的解剖,当然解剖得越深,你会哭得越多,因为你会碰到头痛的问题越多,但是通过这些机制 你可以做很多进一步的优化,但我们原则仍然是首先把代码写正确,然后进行优化。有句老话是:过早优化是万恶之源。
我们既然用 C++ 这样的语言,肯定是想要做优化的,我们一定会要性能,我们一定会要优化,但我们不可能在所有的地方都写出最优的代码,这个开销有点大, 就像前面洋葱原则提到的那样,我们可能会哭死。
三、性能优化

阿姆达尔定律是说我们能够对代码提升性能的提高程度是取决于你的代码在整个程序里占了多大的比例。P代表的是你所优化的部分在你整个应用里的开销的比例。我们想提高执行性能的话,就是执行时间的百分比。Sp 是你提高的部分,打个比方,我如果有一部分的代码在整个应用里面占了50%的开销,那p就是0.5,然后如果我把这一部分的性能整整提高了50%,那Sp就是1.5,代入这个公式就会发现结果是1.2,我们性能总体提升了20%。想象一下,如果我们把某一部分性能提高了100%,但是这一部分占整个系统运行开销的1%,那我们现在能提高多少?只有百分之零点几,哪怕这个东西提高了无数倍,也不可能超过1%的性能提升。所以我们软件要做优化的话,一定要找出瓶颈,来优化这个瓶颈。
所以下面我们要讨论的一个问题就是性能的测试,性能的测试有一个测不准问题,我们这边稍微展开一下:

大家可以稍微看一眼这个小例子,我们想测试的是memset的性能,左边是memset,右边是一个简单的 for 循环来进行清理,我们循环若干次,想看最后这两个clock减一下,得出我们输出执行时间的差异。

可以看到在O0的情况下,memset比手工循环要快出50倍以上,memset 似乎比较快,O1 这个比值就减少了,O1、O0零是不是更接近真实呢?再看O2,会发现出了一个很奇怪的鬼,memset比手工循环慢了10万倍,第一次碰到这个问题肯定就是满头雾水了,原因很简单:对 buffer 的写入被优化掉了。如果你出现了memset 比手工循环慢,那可能的原因就是 memset 没有被优化掉,把手工循环完全被优化没了。我们有时候就会想到 volatile 能不能帮助解决这个问题。

这是个执行结果,我们可以看一下,看起来似乎正常一点,加入 volatile 之后我们会发现 O1 和 O2的结果一致了,都是memset大概是手工循环的性能的5倍,这是不是最后的结果呢?还不是。因为 volatile 本身会妨碍优化。

我们可以看一下,同样是手工循环写入,一个是有 volatile,一个是没有 volatile,然后我们看一下汇编,对于有 volatile 的我们发现汇编里面编译器产生的这个代码就是很老实的,一次写一个字节,一共循环80次,写入到内存里面去,就这么简单,右边这个代码就不一样了,我们会发现编译器连循环都没有了,直接一次写16个字节,连续展开写五次结束,很明显右边这个代码的执行性能肯定比左边的高,这是可以想象的一件事。

所以我们测试的角度来讲就一定要防优化,有时候我们要让编译器不要做一些不必要的优化,volatile 是得谨慎使用,它确实可以防止优化,但有时会防止得过头,而且它虽然能够防止编译器的重排序,但防止不了处理器的重排序。使用全局变量肯定是有好处的,你往全局变量里写一定会写入,如果往本地变量里写,那编译器有可能就把这个东西完全优化。还有用锁可以当简单的内存屏障,这是比较可靠的 C++ 内存模型,能保证在这种情况下性能是令人满意的,但用锁的话性能开销就会比较大,时间会比较大,我们还可以使用 noinline 来防止一般的内联。但不管怎么样,我们可以发现如果把这些东西组合在一起,我们测试精度就需要提高,用clock 实际上是有点问题的,特别在Windows下它的精度太低了,应该只有1毫秒的精度。
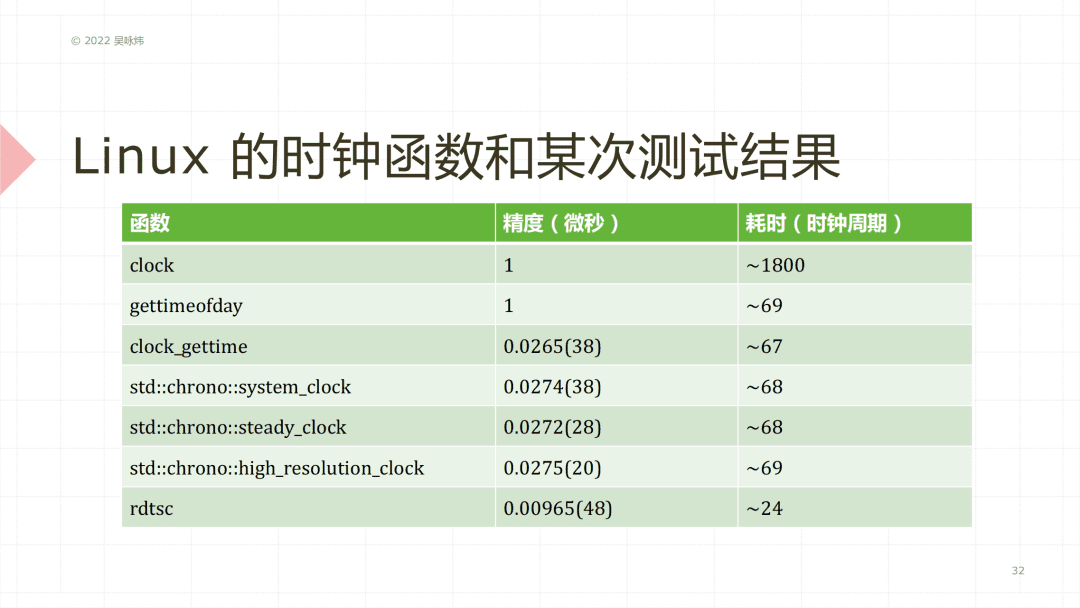
在 Linux 下 clock 的精度稍微高一点,能达到1微秒,但我测过一个结果,它的耗时比较大。实际上我们可以看一下这里面,最优选的,在 Intel 平台上应该是个叫 rdtsc 的一条指令,它一般有内联汇编,可以直接使用 rdtsc 这个函数,精度达到了 10 纳秒,比其他的都要高,开销也要低一点。如果你没有 rdtsc,就可以考虑系统里面提供的 system_clock,steady_clock,high_resolution_clock 三个 C++ 里带来的时钟。我一般会推荐 steady_clock,因为它能够保证时钟是稳定的,保证你测试的过程中不会因为有某个进程进行系统的对时之类的操作,发生时间反转之类的情况。利用这些东西,我们实际上就可以测出比较高精度的结果。

这是我利用前面说的加锁、rdtsc 等等去测函数调用和虚函数调用的额外开销的差异问题,我测出来的一个结果:每次函数调用的开销本身大概是2.5个时钟周期,虚函数调用的开销大概是4个时钟周期,这两个开销本身的差异不大。不过我们后面会提到,虽然这看起来差异不大,但实际上仍然有问题,而且我这个测试实际上是有一点点问题的,因为在测试当中很有可能你调用的函数会变热, 也就是说多次调用了,就会在缓存里,你每次执行就会性能比较高,但实际情况下有可能不在缓存里,这样的话性能差异就又会变大了。但也有很多其他因素,我们后面有个例子可以具体再看一下。

性能测试有两种方法,前面说的就属于是右边这一种“插桩测试”,这实际上不是最优先的测试方法,它适用于已经明确知道瓶颈在某个函数的情况下,就盯着这个函数去测,看看怎么样能够提高这个函数的性能。一般来讲,你在找瓶颈的时候会使用左边这种“采样测试”,采样测试一般需要编译器或者是操作系统来提供一些支持。GCC 本身有个 gperftools,但用起来并不是特别方便,一般我推荐是 Google 的 perftools 会好一点。Linux 本身也有个 perf,这些都是比较好的采样测试的方式,一般来讲比较推荐用采样测试来找出性能瓶颈点,然后在后续的测试当中可以考虑用插桩测试来把你想要提高性能的那个函数的性能精确地测一下,把它性能提高。

总体来讲,我们要考虑90/10的规律,也就是说我们优化的一定是在瓶颈上的一部分代码,剩下的部分就可以不用去优化,或者说等前面的优化完了再去优化,因为我们需要考虑生产率和性能的权衡问题。如果你把时间大量耗费在没有必要的优化上,那你总体生产率就太低了,有可能这个程序的性能反而提不上去。所以再强调一遍:过早优化是万恶之源。

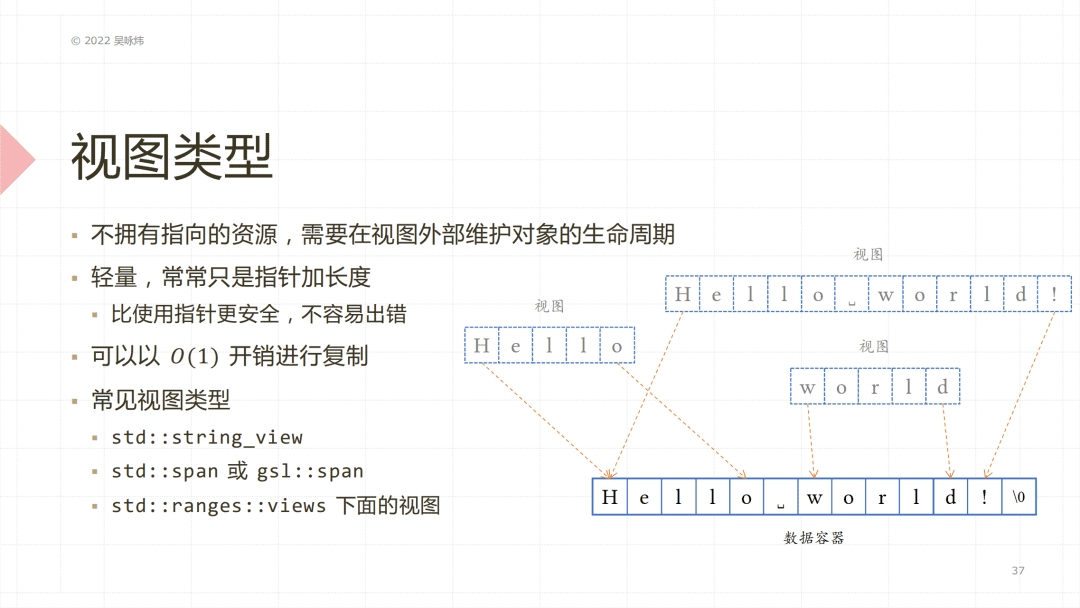
视图类型是说某一个对象不拥有指向的资源,一般来讲它只是指针加长度这样轻量的东西。但它用起来比较方便,我们利用 C++ 里面的一些构造和隐式转换可以很方便地使用视图,同时可以对接口进行同一化处理。只要你保证底层的数据一直存在,那我们实际就可以使用指针加长度这样一个比较轻量级的对象来访问。这样一个视图类型对象的复制开销为 O1,所以做传参的时候拷贝这个或者新构造这样一个对象都比较方便。我们常见的视图类型有 string_view,这是 C++ 17 里有的;然后 C++ 20里面会有span,或者你等不及 C++ 20 的话,只要你使用 C++ 14 以上的版本,可以用 gsl::span。C++ 20 在 ranges 下面还有好多的视图,这些视图用起来都非常方便,而且性能还非常高。这就是C++ 提供d的一种抽象方式,来帮你解决一些性能问题。

优化选项也是另外一个和性能关系很大的东西,像 GCC 下面有一大堆的优化选项,细分的话大概一共有100多个,这里就不一一例举了。我们看一个很具体的例子。
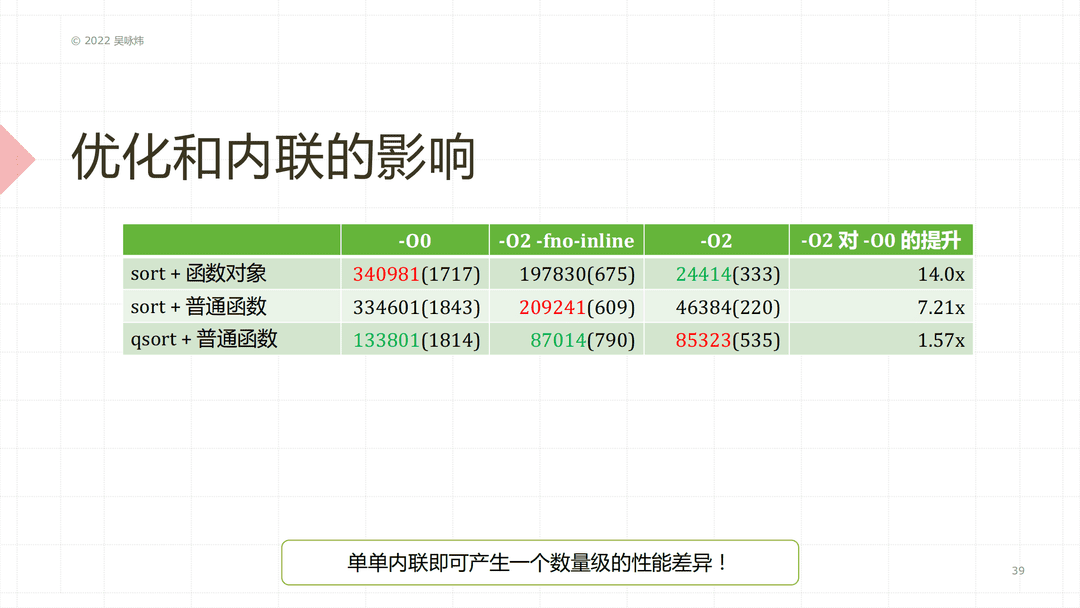
这个例子里面,我有3个测试,一组测试是 sort 加上一个函数对象,我用的是 less;然后是 sort 加上一个普通的函数,就是你写一个函数来比较两个东西的大小,我利用这个函数指针去传给sort 来进行排序;还有一个就是 C 里面就有的 qsort,也是利用一个普通函数来进行排序。我们会发现在 O0 的情况下,C 性能会比 C++ 的要高,但一旦你开到了 O2,C++ 代码的性能就反过来比 C 的要高出很多了。而且我们可以看一下 O2 对 O0 的性能提升,在 sort 加函数对象的情况下是14倍的性能提升,而对于 qsort 是 1.57倍,换句话说,在 C 的年代,你可能可以承受得了不开O2、O3,但在 C++ 的年代里恐怕有点难,因为你不开这些优化选项的话,你这个代码可能会发现性能很低,因为标准库里的很多东西,如果你不开优化,特别是没有 inline 的话,是绝对不可以的,因为 inline 不 inline,本身就可以带来一个数量级的性能差异。
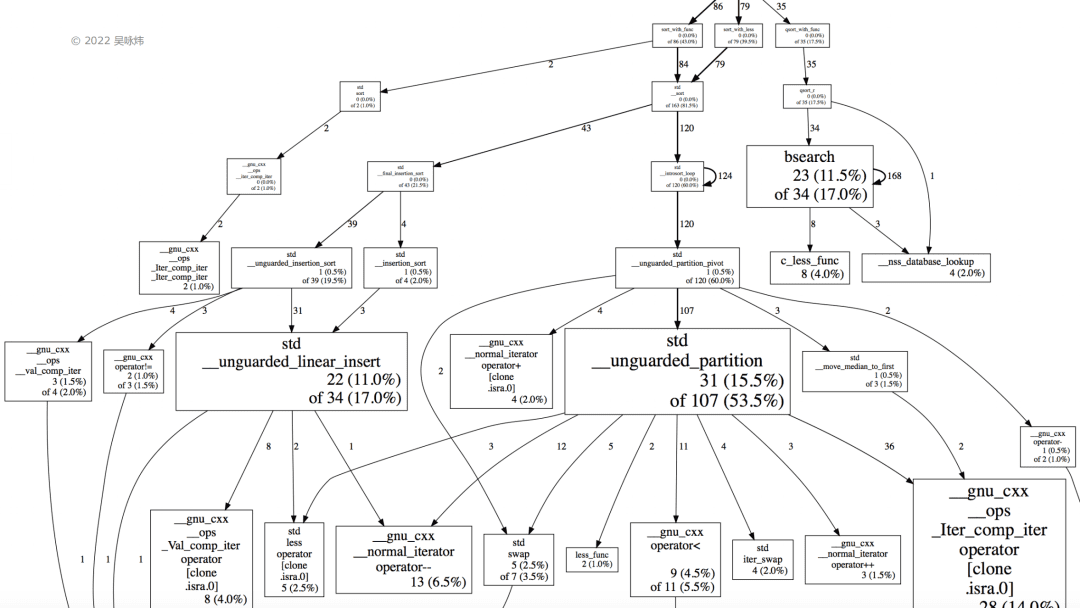
我们看一下这张图,上边左边是sort_with_func,中间是 sort_with_less,这两个就是前面说的使用函数指针和使用函数对象。我们可以发现这个函数调用非常复杂,就是因为 sort 函数里实际上是有很多层的函数调用。C++ 里有很多小函数,每一个的圈复杂度都比较低,而 C 的话,大家会发现它的函数调用层次不深,就这么几个函数,所以它能够容忍你没有inline、没有优化,都还可以。但是 C++ 里就不行。C++里你要达到比较好的性能,一定要开高优化,一定要打开inline。



Q&A
Q. 函数对象为什么比纯函数快?
A. 因为函数对象比纯函数更容易被内联,这是最主要的优化点。
Q. 采样测试需要权限吗?
A. 采样测试用perf一般需要root权限。如果没有root权限,可以考虑使用 Google Perftools。
Q. 虚函数和模板?
A. 模板是静态多态,虚函数是动态多态。一般来讲,模板能够做到更高的性能。
Q. 编程语言的抽象性影响性能是什么意思?
A. 是指你写下一行语句,有可能不知道背后发生了些什么事情,你需要理解这个语句背后发生了什么事情,你才知道这个东西对性能有什么关系。
Q. 工程上很多的性能瓶颈来自于加锁、IO 等,那对于 C++ 语言本身的一些优化是否一般来说并不是性能瓶颈?
A. 我觉得不会这么说,因为首先你需要理解什么情况下该使用加锁,什么情况下不需要使用加锁。其次,当解决了一些其他的瓶颈之后,语言本身就可能会成为瓶颈。我们肯定不希望瓶颈一直是在加锁或 IO上,一定是要想到办法把这些瓶颈撸掉,而且在这个过程中你也需要利用到 C++ 的一些特性。
Q. Lambda 和函数对象的关系?
A. Lambda就是函数对象,所以我前面提到函数对象的东西跟Lambda 是共通的,Lambda 就是一个匿名函数对象,自动帮你生成了一个函数对象。
Q. bind 性能为什么低?
A. bind产生了一个对象,里面做了类型擦除,调用它时需要做一次类似于虚函数这样的转发。肯定比不上 lambda,因为如果你用 lambda 的话很大程度上可以做内联,bind 很多情况下不能内联。一般来讲,现代 C++ 已经基本上没有什么需要用 bind 的地方了,都可以用 lambda 代替。
Q.如果用 pool allocator 1000大小的map是不是也可以一次性malloc?
A. 不会,只是说你向系统申请内存的次数少,但 map 本身还是会执行 1000 次的分配,最关键在于你内存的局域性不一定能保证。当然如果你的 pool allocator 做得好的话确实可以优化到接近于我前面说的 vector 这样的程度。事实上这两种都不一定是最优化的情况;取决于你具体的使用场景,可能可以进一步优化。比如说我在实际项目里有一种优化的场景是 map 基本上是不变的,这种情况下我可以进一步优化到运行时没有初始化开销,完全静态,这种情况下运行时只是做一个查询,而没有任何分配开销了。
Q. vector 1000次的测试数据是不是跟 CPU 有关?
A. 可以这么说吧,具体肯定需要自己测的。我这个数据我相信是具有一定普遍性的,但肯定也有平台相关性,跟 CPU 可能有一定的相关性。跟 OS 的相关性只有一点,就是你使用的内存分配器本身的开销怎么样 。
Q. nop 用到自旋锁,低功耗?
A. 我现在是觉得自旋锁并不一定是个好主意,因为我自己设计过一些无锁的数据结构,实测下来,现在无锁的数据结构不一定有性能优势,性能经常还不如直接加锁,因为无锁的情况下意味着没有满足条件的话就会继续往下执行,你会继续占住CPU,你即使 nop 也是占住 CPU 了,因为你是无锁的话,做一个spinlock 肯定会有一个循环,会不停在那转圈,不管怎么样,你会额外做一些操作。如果是加锁的,当前这个线程就没有任何操作,完全交给操作系统、交给我的运行库去调度。
Q. 什么系统才能用到性能优化?
A. 我觉得任何系统都用得到性能优化——如果你不需要性能优化的话,你干吗用 C++?用 C++ 就是为了性能。
Q. Lambda一定要用模板参数接收吗?
A. 当然不一定了,但是你用模板参数接收的话,有望达到最高性能。只有在用模板参数接收这种情况下才能满足我前面说的内联,如果你用function或者函数指针的话,都会降低内联的机会。
Q. 什么情况下使用类型擦除?
A. 每一个函数对象,每个 lamda 都是不同的类型,所以需要用模板参数的方式来接收,这种情况下我们能达到最高的性能。但同时因为它必须用模板参数来接收,所以每一次用不同的对象类型去调这个函数模板,都会产生不同的代码,也就意味着你有可能会有二进制膨胀。这是一种情况。另外一种情况是,你需要用一个 map 或者是 set 或者 vector 来接收一堆不同的函数对象或者 lambda 表达式,这种情况下,因为你需要让这个容器能够放下不同的函数对象,也需要用类型擦除,也就是说让不同的对象变成同一种类型的对象,把它变成同一种类型,我只关心它的参数、返回值等等。
Q. MSVC的优化技巧或工具
A. profiling 用 Visual Studio 本身就自带的,C++ 语言方面实际上是差不多的,这个其实跟平台相关性很弱,主要是profiling 的工具会不一样。Windows 下就用 Visual Studio,Linux 下会用 perf 或者是 Google perftools 这样的工具。
Q. VTune 对于性能分析是不是个好工具或者是否有更好的推荐?
A. 如果你在 Intel 平台上工作的话,那我相信 VTune 应该是最好的工具吧。
Q. STL 的效率够用吗?
A. 你打开优化的话应该是够用的;如果你不打开优化,那肯定不够用。
Q. 分析 RTTI 和异常有什么好的工具和方法?
A.通过普通的性能测试就可以。RTTI 性能取决于你的继承树的深度,继承层数不深的话,一般来讲性能问题不大。异常确实可能性能开销比较大。如果在不抛异常的happy path,执行性能通常来讲是没什么问题,一般会有一些二进制膨胀的问题,但不应该会有执行性能的问题。一旦抛了异常,对执行的性能影响就非常大,所以一般的指导原则是你抛异常的概率应该小于1%,而且不应该是用户可以容易造成的。比如,如果你网络报文不合法就抛异常,这基本上不可接受:因为这意味着黑客可以制造一些非法的报文,让你的系统性能降到原先的百分之一、千分之一,这显然不可接受。所以即使在使用异常的情况下,也不意味着我们所有的错误处理都要用异常。异常要用来处理真正异常的情况。
Q. 编译选项开O3好还是O2?
A. 通常来讲是O3好,当然你要试验一下,性能问题说到底都需要测试,真正你要精调的话不是开O2或O3,至少在 GCC 下不是,而是要了解O2、O3分别打开那些选项,然后真的逐个去调这些选项,发现哪些选项打开是有好处的,哪些选项关掉更好一点。
Q. Linux版本标准库的 malloc 是直接new 的吗?
A. 目前所有系统我了解到的标准库自带的 allocate 都是直接去new的,当然new之后,malloc里会怎么做,那就是你 C 的运行时库的影响了,你到底是使用 ptmalloc,还是jemalloc,还是Google 的 tcmalloc,都会带来性能上的不同影响。用 mimalloc 也是个方法,反正这些额外的这些 malloc库通常来讲都会比默认的运行时库里的内存分配要好一点,当然一定还是要测试。
现代C++性能优化高端培训

相关推荐
-
东莞网络公司推广(网络营销课程)
网站在建成之后做好百度SEO对网站营销推广是非常重要的,东莞网络推广很多优化人员也都投入其中,不断地学习和总结更好的优化技巧,但很多站长们在做优化时经常感觉收获不大,很有可能是没做好相关细节操作。那么接下来,东莞网络推广就带大家一起来了解一下哪些操作会影响到网站优化效果呢?1、用图片代替文本内容一
-
新东方学校简介(新东方属于什么学校)




7月6日上午,新东方济南学校高新会展旗舰校区盛大开业。两百多名教职员工和几百位家长孩子们共同见证了新东方教育科技集团全国最大教学区(之一)的启航。新东方高新校区位于高新区济南国际会展中心西翼裙楼四层,单层面积7000余平方米,致力于为各位学生、家长提供更好的教学体验和服务。新东方教育科技集团助理副总
-
配件销售合同(配件销售什么意思)
金龙机电7月10日公告,公司及子公司自2022年7月8日前连续十二个月内与广东弗我及其子公司滁州弗我、安徽弗我签订日常经营性合同订单累计金额9.19亿元(含税),占公司2021年度经审计主营业务收入的49.49%。合同订单约定公司及子公司向广东弗我及其子公司提供电子雾化器及相关配件生产等内容。上述电










版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请通知我们,一经查实,本站将立刻删除。